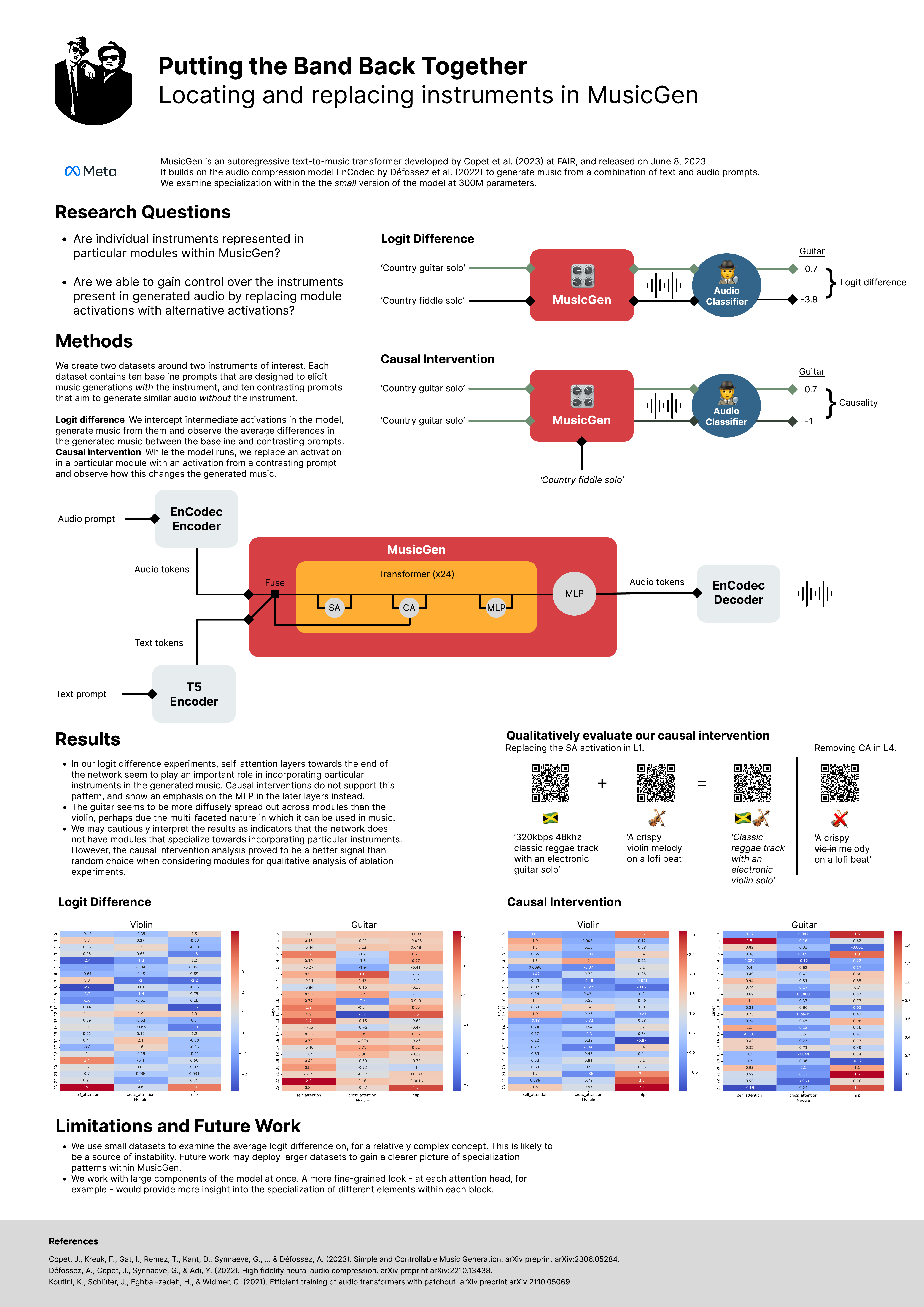
Mechanistic Interpretability Experiments with MusicGen
Jamie Vlegels and I did a short, 3-day project digging into specialization within MusicGen and were lucky enough to be awarded Best Poster for it at the University of Amsterdam's end-of-year student conference. (Scroll down for audio examples)
Audio example
Here's a fun example of how we gained more control over the audio generated by MusicGen. Guided by the heatmap obtained from the causal intervention experiments (lower right on the poster), we tried replacing the activations in a couple different modules and found that the self-attention in the first transformer block produced some cool-sounding results.
We first generate a sample using the prompt '320kbps 48khz classic reggae track with an electronic guitar solo'. It sounds like this:
We also generate the audio for 'a crispy violin melody on a lofi beat':
We then redo the guitar generation, but this time we pause execution when the model reaches the self-attention module in the first transformer block. We discard whatever the module computed (before the residual) and replace it with the activation from that same module when we ran the violin-based prompt. Now we continue execution as normal and listen to the result.
We thought the result was pretty cool! There is much less guitar in the track while preserving the reggae vibe, and there is now an electric violin-like melody there that resembles the one from the unmodified violin generation.
Do take a look at the Limitations section on the poster.