Neural Radiance Fields
Table of Contents
Conventional methods of rendering 3D objects and spaces specify geometry and material properties in some format, like a polygon mesh -- made out of vertices and edges -- for geometry, a texture map for color and a normal map for light reflection properties. You then simulate a viewpoint using that information and physics simulations.
A Neural Radiance Field (NeRF), designed by Mildenhall et al.1, takes over the role of the file format and part of the rendering step in the form of a neural network. Once trained, it takes a world coordinate and a viewpoint, and returns an RGB tuple and a density. If you interrogate the NeRF enough you can render any traditional 2D image or 3D from it by combining all the data points.
Here's a video from the website that accompanied the original paper showing 360 views generated from a number of different NeRFs:
The advantages a NeRF versus a traditional 3D model are:
- A NeRF is trained on known views of a scene, like a set of images coupled with info on where they were taken from. If you're looking to create 3D models of real-world objects, this is more direct than manual 3D modelling.
- A NeRF is a continuous function, so in theory its resolution is infinite. In practice the resolution is bounded by the capacity of the neural network used and the level of detail in the training images.
How does it work?
Model architecture
The NeRF design implements a function that maps a world coordinate $(x,y,z)$ and a viewing direction or pose2 $(\theta, \phi)$ to a color $(r, g, b)$ and a density $(\sigma)$.
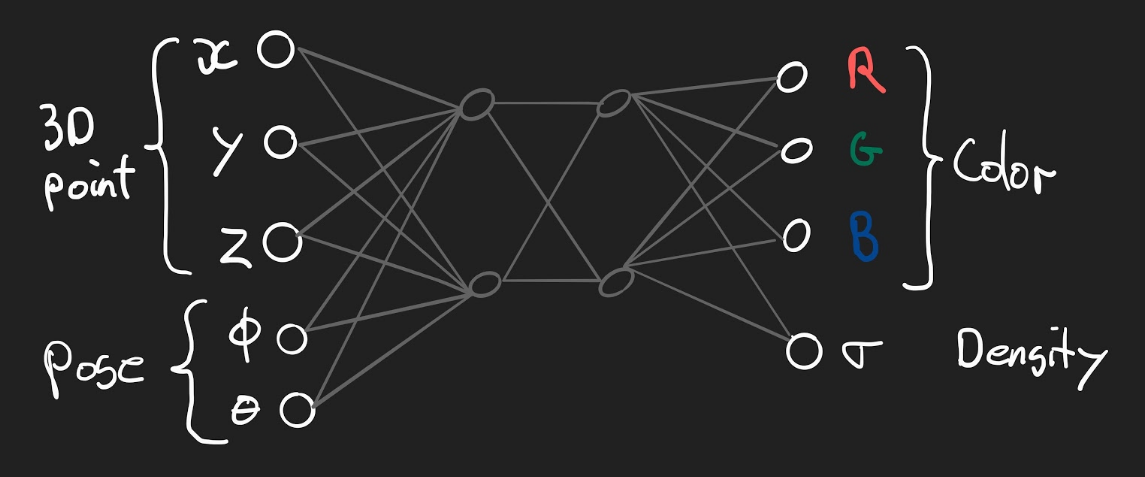
Density is what you would expect it to be: an abstract measurement of how dense the material at the specified location is. In mathematical terms, the function is:
$$F_\Theta: (x, y, z, \theta, \phi) \rightarrow (r, g, b, \sigma) $$
Model architecture bonus
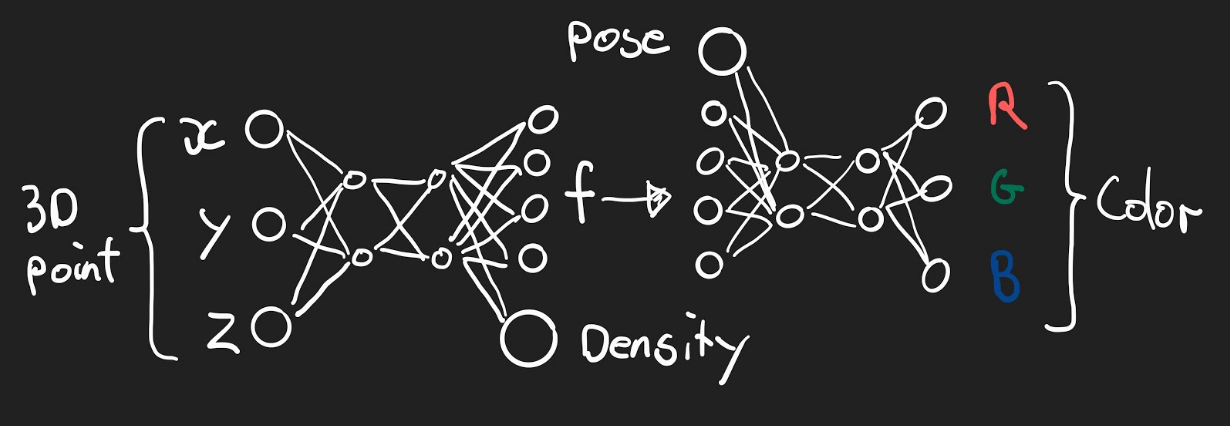
Since density does not depend on the viewing direction, the NeRF is actually made up out of two separate, linked networks. The first maps a world coordinate to a density and an abstract, 256-dimensional feature vector. The second network maps this feature vector and the viewing direction (pose) to a color.
Generating views
A fully trained NeRF holds an abstract representation of a scene in its weights. It returns colors and densities as if you were actually looking at the scene from the given direction. An algorithm to generate a regular image from a NeRF is volume ray casting:
- Position a hypothetical camera in the NeRF world. Specify the camera's position, viewing direction and focal length.3
- Send out hypothetical rays from the camera out onto the scene and sample points from the NeRF along the ray. Each ray is going to determine a pixel's color.
- Decide which color the pixel gets based on the color and density of the samples along the ray. In the paper1 the exact function comes from a paper by Nelson Max.4
- Put all the pixels together to produce an image.
3D Model Extraction
A way to build a 3D model based on a NeRF is:
- Map out the scene geometry by using marching cubes.
- Decide on the colors by probing the NeRF using the geometry itself as the world coordinates and the surface normals as viewing directions.
Training
Neural Radiance Fields are trained with images of the scene and information on where the training images were taken from. You compare the training images with identically positioned ones rendered from the NeRF and minimize the reconstruction error.
Obtaining camera pose information for training images is not part of the NeRF algorithm. I suggest COLMAP, an open source toolkit that matches points across images in a SIFT-like way to retrieve camera matrices from a set of images. With COLMAP, I had more success with relatively wide-angle shots (35mm) compared to portrait-style images (50mm).
What are the open problems?
Here are a few open problems and some approaches to solving them.
Training Speed
The original NeRF algorithm is slow, especially when compared to photogrammetry, a non-machine learning object scanning method. In a project I was involved in, a state of the art proprietary photogrammetry method could process ~80GB worth of 24MP photos into a micrometer-level accurate 3D model in about 8 hours, while the fastest NeRF implementation took the same time to train a model on just 46 pictures at 0.2MP.
On the other hand, it may not be necessary to use equally high-res training images to reach competitive image quality. A NeRF is continuous function, so it may correctly fill in details based on relatively little data. In addition, photogrammetry requires a much more controlled image capturing setting and is more prone to errors in the data gathering step than NeRF.
Inference speed
Generating views directly from a NeRF is quite slow. For a 2D image, multiple inferences are needed to find the color for a single pixel. It takes 20 to 30 seconds to render a single 800x800 image, depending on the hardware and implementation used.
There have been a number of papers suggesting algorithmic improvements in the rendering step. The most recent ones are those by Hedman et al.5, Yu et al. 6 and Garbin et al. 7, which each propose their approach to baking the NeRF into another representation that can be queried at higher framerates.
Post-Training Flexibility
Once trained, a NeRF contains an implicit representation of a scene in its weights. That means all the principles of neural networks being black boxes apply. The geometry, color, lighting, reflections, and any other properties that affect appearance are all baked in. Here are some challenges and proposed directions to solve them:
- Relighting. Bi et al.8 propose a different model design that not only incorporates a separate density variable $(\sigma)$ -- like NeRF --, but also a separate reflectance model, to enable relighting. Srinivasan et al.9 also published a paper on relighting NeRFs, proposing that each point in the field also returns material parameters and some vectors that indicate how visible the point is from different directions. This is enough to simulate new lighting conditions.
- Composition. It would be great if multiple NeRFs could be combined to form more complex scenes. Ost et al.10 propose Neural Scene Graphs, which are hypothetical worlds with multiple NeRFs that each embed a single object. Each NeRF also has an affine transformation between the world and camera space associated with it. This positions it somewhere in the scene world and allows transforming sample rays accordingly at render time to produce a coherent novel view. They learn the background of the scene separately, and all do all this dynamically from the frames of a video. See Guo et al. 11 and Niemeyer et al. 12 for other approaches.
More
There's a lot more to explore. You can find a curated list of papers that build on the NeRF design on GitHub: yenchenlin/awesome-NeRF. If you thought this was cool, you might be a nerd (in a good way). Come back later for more, and follow/DM me on Twitter! 🤓
References & Footnotes
Specified in the spherical coordinate system without the distance from the origin $(r)$, because only the direction is of interest.
In other words: define the internal and external camera matrix.